
When programming with P8, one recurrent task is counting how many results a query has.
There are a few options to do this, none of them being count(*) and I’ll explain why. The purpose of this post is to expose them and compare their execution time and limitations with benchmarks. We will also see how to optimize each of them separately. Hopefully, after reading this post, you will be able to choose which one best fits your needs. Before introducing all options IBM made available to us, a little introduction important to understand this post and its benchmarks.
When counting, it may be strange, but it is a lot better to expect something. Or if you can’t, at least have a limit over which the result doesn’t really matter, you are happy enough knowing it is more than this limit. Actually in most case that’s enough. For UI you would say over something, to forbid an operation you usually have a limit over which you will forbid it anyway, and so on. Of course, if you want the exact number of item, it can be done but it will be a lot slower.
Benchmarks will be counting the number of documents in a 5/4/10 folder hierarchy, meaning 5 level of sub-folders, each level with 4 sub-folders and 10 documents. This is about 55,000 documents in 5,500 folders. And we don’t always want to count exactly, in the benchmarks we will ask if there is more than 5, 10, 15,50 … until 40,000 documents. Because sometimes knowing than there is more than 50 documents is enough to forbid an operation.
Now let’s introduce the few options we have to count.
Contents
Introducing the different options
Why not count(*)
Some of you may wonder why we don’t have a count(*) available like in any other SQL language. This is because P8 is not only a DBMS, since it has to apply security on each row it will return. That’s why you can’t use count(*), because FileNet will have to analyze each item anyway to check if you have sufficient permission on it or not. We could still think that it would be nice to get only the number returned anyway, instead of returning all IDs, well it’s done in P8 5.2, with the new COUNT_LIMIT option :). If you really need to use a count because you have million on documents, don’t care about security and just want to know how much precisely, you can still query the DB with a count(*).
Count all results by iterating them on a non paged query
I thought I wouldn’t speak of this one, thinking it would be inefficient, but I actually had some unexpected results, so let’s talk about it. I don’t really have to explain how it works since it is pretty basic. Just do the query (fetching only Ids of course) and iterate until there is no more result. We use continuable = false, therefore the query is not paged and all results are returned on the fetchRows, which can be dangerous and used a lot of memory, so this solution is to be used really carefully.
How to limit: in this method, the limitation comes with the TOP keyword in the SQL, or setMaxRecords for the helper SearchSQL.
Limitations: The result is limited by the NonPagedQueryMaxSize property from the ServerCacheConfiguration object, which is 5,000 by default. If you use a higher value in the query, this property will override your limit anyway. If you need to count past this, you will have to change this value. You can use the same procedure than for changing the page size, explained here.
SearchSQL sql = new SearchSQL();
sql.setSelectList("d.Id");
sql.setFromClauseInitialValue(ClassNames.DOCUMENT, "d", true);
sql.setMaxRecords(limit);
sql.setWhereClause("d.This INSUBFOLDER '/Test'");
SearchScope sc = new SearchScope(os);
int count = 0;
RepositoryRowSet rrs = sc.fetchRows(sql, null, PropertyFilters.pf_Id, false);
Iterator<RepositoryRow> it = rrs.iterator();
while(it.hasNext()) {
it.next();
count++;
}
System.out.println(count + "documents");
Count all results by iterating them on a paged query
This solution is almost as the previous one, however we use a paged query. This means we won’t get an excessive amount of used memory, the fetchRows will be faster, but the iteration will be slower since interrupted by a round trip to the server every pagesize items. Here we use continuable = true, therefore the query is paged. Only the page size is limited, but that’s not a problem since we can have as much page as we need. Here we are using 1000 which gives a descend speed, without having to increase the QueryPageMaxSize property. (See optimization section for more information about he page size effect on the execution time)
How to limit: in this method, the limitation comes with the TOP keyword in the SQL, or setMaxRecords for the helper SearchSQL.
Limitations: There is no real limitation with this option. The page size is limited by the QueryPageMaxSize property, but the actual number of results returned isn’t limited.
SearchSQL sql = new SearchSQL();
sql.setSelectList("d.Id");
sql.setFromClauseInitialValue(ClassNames.DOCUMENT, "d", true);
sql.setMaxRecords(limit);
sql.setWhereClause("d.This INSUBFOLDER '/Test'");
SearchScope sc = new SearchScope(os);
int count = 0;
RepositoryRowSet rrs = sc.fetchRows(sql, 1000, PropertyFilters.pf_Id, true);
Iterator<RepositoryRow> it = rrs.iterator();
while(it.hasNext()) {
it.next();
count++;
}
System.out.println(count + " documents");
Count by iterating only the pages
Here we use the page Iterator instead of the iterator, and ask to each page how many elements it has.
How to limit: in this method, the limitation comes with the TOP keyword in the SQL, or setMaxRecords for the helper SearchSQL.
Limitations: There is no real limitation with this option. The page size is limited by the QueryPageMaxSize property, but the actual number of results returned isn’t limited.
SearchSQL sql = new SearchSQL();
sql.setSelectList("d.Id");
sql.setFromClauseInitialValue(ClassNames.DOCUMENT, "d", true);
sql.setMaxRecords(limit);
sql.setWhereClause("d.This INSUBFOLDER '/Test'");
SearchScope sc = new SearchScope(os);
int count = 0;
RepositoryRowSet rrs = sc.fetchRows(sql, 1000, PropertyFilters.pf_Id, true);
PageIterator pi = rrs.pageIterator();
while(pi.nextPage()) {
count += pi.getElementCount();
}
System.out.println(count + " documents");
Let P8 counts (5.2 only)
An other option has been introduced in P8 5.2. The COUNT_LIMIT option, available only on paged queries. This makes the method PageIterator.getTotalCount() (since 5.2 API) available if counting is enabled on the server (it is by default). This makes the code really easy to read, and is faster than other paged queries. However it comes with a few limitations:
The result is not always precise, for example if there are less results than the page size, the returned value is null. A workaround can be to use a page size of 1, we will see in the optimization benchmark the performance impact of such a workaround. If there is more results than the page size -limit is returned. Hence to get the exact number, you need to have a limit higher than the actual number of documents, and a page size lower than that, and of course the Cache Configuration of the server with a QueryCountMaxSize as least as high as yours. That’s a lot of conditions :).
How to limit: in this method, the limitation comes with the option itself, there is no need to use the TOP keyword like in the other options.
Limit: The result is limited by QueryCountMaxSize property of the ServerCacheConfiguration, if its value is 0 then counting is disabled on the server. To change its value, you can use the same procedure as for changing the page size, explained here. If there are less results then the page size set, then it returns null and we don’t know how many results there are exactly, but again, sometimes it is enough because we just want to know it there are more than a certain limit.
SearchSQL sql = new SearchSQL();
sql.setSelectList("d.Id");
sql.setFromClauseInitialValue(ClassNames.DOCUMENT, "d", true);
sql.setWhereClause("d.This INSUBFOLDER '/Test' OPTIONS (COUNT_LIMIT " + limit + ")");
SearchScope sc = new SearchScope(connector.getObjectStore());
RepositoryRowSet rrs = sc.fetchRows(sql, 1000, PropertyFilters.pf_Id, true);
Integer count = rrs.pageIterator().getTotalCount();
System.out.println(count == null ? "null" : count + " documents");
See the line 8, the getTotalCount() returns null if the number of results is inferior to the page size, in our case 1,000, so take care of handling this case. You can of course use a page size of 1 to have the precise number. We will see the performance impact on the optimization benchmark.
Comparison
Here are some benchmarks to compare these four solutions. As always, I run my benchmarks in local, LAN and over the Internet. In local means on my laptop with a VirtualBox VM (5400 tr/m disk…), LAN is over 100M LAN targeting my ESXi server, which is a lot more powerful (i7 4 cores, 16GM of memory and a SATA disk), and finally I target the same server over the internet, over a 30/3M (DL/UP) connection.
Local allows me to see what happens if the server is struggling with resources (mostly HD and little bit processor actually), LAN is usually a nice balance between network and machine resources, and over the Internet allows me to see what happens with the network as bottle neck. As I said, this is counting in a folder with about 55,000 documents in its descendants, on a platform containing only these 55,000 documents, which is relevant (I’ll write about that too later). For the page size, I used a good balanced value find in the optimization section, which is 1000.
Also I wanted to say that since queries are made one after the other, there is cache mechanisms (DB and disk) making it faster. However, I tried without cache. which wasn’t easy, I took a running snapshot of all VM and restored them before each query. That, at least, removed the DB cache, I’m not sure about the disk cache, because the hypervisor might have kept something. But anyway the differences were significant but proportion between methods stays the same and we can make the same conclusion. I will post these result anyway in a collapsible section at the end of this post.
Warning: I increased the QueryCountMaxSize and NonPagedQueryMaxSize to 60,000 in order to be able to count over the default 5,000 limit, until my 40,000 documents. This is a lot for the NonPagedQueryMaxSize and I wouldn’t recommend it on a production platform. I did this only in order to compare the non paged query until the 40,000 documents count.
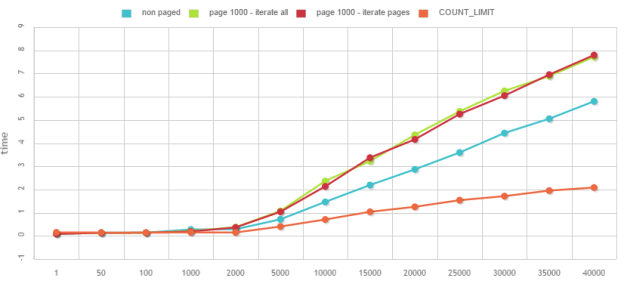
The x axes is the maximum number of documents we are willing to count (the limit), the y axes is the execution time in seconds. There are 4 lines, one for each options.
Since this is a pretty common task to count below 1,000 documents, let’s focus on that part. I removed “iterate all” since it’s almost the same as iterate pages. I know it’s a lot in one graph but you can click on legend to hide some series and look at what interests you 🙂
What can we say from this benchmarks? Of course everyone is free to disagree with me.
First the non paged query:
Pros:
- This is really fast, on the server the query is faster, and on the client it’s a basic iteration so almost instant even for millions of rows.
Cons:
- You have to transfer all IDs via the network, which can slow things a lot, this is what we observe on the Internet graph.
- It consumes more RAM on both side, but seriously with the size of an ID, you’ll have to count hundreds of thousands of rows before reaching 100Mo RAM…
- You need to increase the
NonPagedQueryMaxSizeuntil the limit you wish to count, that could be really dangerous if other developers don’t know what they are doing and fetch more than they need.
The paged queries (I’ll speak about both together since results are almost exactly the same):
Pros:
- You don’t have to increase any limit in the server Cache configuration.
- You are safe with the RAM consumption.
Cons.
- This is amazingly slow because you are making server round trip for every pages.
- You transfer every ID via the network.
- It looks like it needs a lot of resources for the server. Don’t really know why, maybe build pages and requests.
Finally the Count_Limit option (P8 5.2 only):
Pros:
- You transfer only the number via the network, which is amazing news for slow network, at a matter of fast, you can see numbers are exactly the same between LAN and Internet (remember this is the same platform), which means this feature almost doesn’t rely at all on the network.
- There is no RAM on the client used since we don’t store anything.
Cons:
- It seems like it needs more resources on the server than the non paged query. But as soon as the network isn’t great, the IDs transfer for the non paged query becomes slower than that anyway.
- You have to increase the MaxCountQuery parameter but that’s what’s for anyway, so why not.
Conclusion:
Well, of course it depends a lot of how many documents you are counting, and what is your architecture. I’ll try to summarize as much as I can here.
If you are counting a small amount of documents, even in large folder, they are all pretty much the same but the Count_Limit is not as precise as the other since if you are below the page size, it will just tell you that you are below and that’s it, so I would use paged query which is safe and won’t consume much memory. However you need to be sure you won’t go over a 1,000 limit because then it gets really slow.
Now if you are counting large folder until high limit… if you are using 5.2, go ahead and don’t over think, use the Count_Limit option. You might envisage the non paged query if you need very high optimization (or have no clue about what you’re counting, see optimization section), but then you’ll have to have a perfect network, a lot of memory, and they might be side effects. I would recommend using the new feature because the gain is not significant for such a risk, and as soon as the network slows down, the Count_Limit is better on every aspects.
If you are using 5.1 or earlier version, then it depends of what you want to do, here the difference is significant so I would use the non paged query if I know I will count small amount, but for larger if I am not looking for great performance, I would play safe and use a paged query, because then I don’t have to increase any value in the server configuration and don’t take any chances, but that will be slow for large folder, just deal with it or upgrade to 5.2 🙂
If you are looking for the best performance you might envisage non paged query but be aware that you’re network need to be great or this will be slower that Count_option anyway, adjust the heap size on both size accordingly (again ID’s are not so much memory consuming but still)
My comment:
I really wasn’t expected such good result with a basic non paged query, I was really surprised about that. Although I’m really excited about the new feature of 5.2 and will definitely use that when I can. It took them a few years to come up with that feature but it was definitely worth the wait, we finally have a good way to count!
Optimization
You can choose whatever option you prefer, we will see in this section how to optimize each of them depending of the approximate number of documents you intend to count.
Here is the effect of the page size on the execution time for last 3 options (obviously it can’t be done with a non paged query 🙂 ). I progressively increased the page size from 50 to 40,000 (all results in one page) with different limits for the maximum number of documents to count. This way you can see the impact of the page size depending of how many documents you intend to count.
Warning: To pass the 1,000 default max page value, you will have to change the QueryPageMaxSize property of the ServerCacheConfiguration object, as explained here. I set it to 40,000, which is huge and will use quite a lot of memory. This is for the purpose of these benchmarks only and I wouldn’t recommend it on a production platform.
Paged queries
See benchmarks
As you can see on the benchmarks, the page size has a huge effect on execution time. You can’t see it on the benchmark but it was funny to see that with small page size, the HD wan’t even working much but processor’s core was 100% and network used a lot. That shows that with a small page size, the server actually spend most of it’s time building the request, and besides having a slow query, you will also slow your server.
We reach sufficient performance with a page size of 2,000/3,000, and the gain over this size isn’t worth the memory usage, and execution time is actually slower over 5,000. So use a large page size, 1,000 if you don’t want to change the default max page size value, 2,000 or 3,000 if you are willing to. This might fast a lot your query.
I won’t do this for the iterate all since the benchmark is almost exactly the same. And the best page size would be also between 1,000 and 3,000.
Count_Limit option
See benchmarks
This one is super interesting, and I really wasn’t expecting such a chart, and executed the benchmark a few times to make sure. There is a lot to say on that 🙂
First, see how the query is slower when you are limiting to high number but using a small page size. I can’t explain it, but we can’t argue with that… counting until 40,000 is 63x slower with a page size of 1 than 10,000! (32s against 0.51s) This is frustrating because remember, when the actual number of documents is lower than the page size, it’s all the query says (it returns null). So if you need an exact number and have no clue if there is 1 or 40,000 documents, then you need to use 1 as page size, with which performances are not good if you are unlucky and there actually is a lot of documents, but at least you’ll have the exact number if there isn’t.
Another interesting thing is see how the line rise for low limit with high page size, actually counting 100 docs or 40,000 take the same time if your page size is 40,000. My guess is the Count_Limit count until your page size anyway, even if you are asking for less, that’s strange.
To summarize, If you know you are counting a small number of documents, choose a small page size to be precise, as you can see on the graph it will be fast anyway. If you are counting a large folder, and you know it’s large, use a page size of 2,000, this gives really good result and you will be precise since the count is higher than the page size. If you have no clue about what you are counting, and need to know exactly if there is 2 documents or 40,000, there is nothing you can do, choose 1 or 2 of page size and wait.
Another solution would be using a iteration query (paged or not paged), which are proportional in execution time/number of documents and always exact, but then this will be slower if you actually have a lot of documents.
Without cache
Now, for whose who are still reading, I don’t think much people will do but still… Of course in real life, we won’t run the same query over and over again and data won’t usually be in the DB or disk cache. I tried to reproduced that to compare the different type of queries. Although I guess all of them have at some point to look for all the documents but they might do it in a different way. To simulate this, as I said at the beginning of this post, I took snapshots of the VM right after the platform started and restored it before each query. However the hypervisor could still keep some things in HD cache so of course that’s not perfect but this is to get a glance of information when data are not all in cache. Here are the results for all three scenarios: Local (VM), LAN (ESXi), Interet (ESXi)
See benchmarks
Really nice article! Thank you for sharing this.
Really nice article indeed! Is there a way to use an offset in your queries?
I have to handle 100 million documents and in the query i have to save the last document handled and continue from there.
Maybe saving the paging is an option?