
When programming with P8, one recurrent task is counting how many results a query has.
There are a few options to do this, none of them being count(*) and I’ll explain why. The purpose of this post is to expose them and compare their execution time and limitations with benchmarks. We will also see how to optimize each of them separately. Hopefully, after reading this post, you will be able to choose which one best fits your needs. Before introducing all options IBM made available to us, a little introduction important to understand this post and its benchmarks.
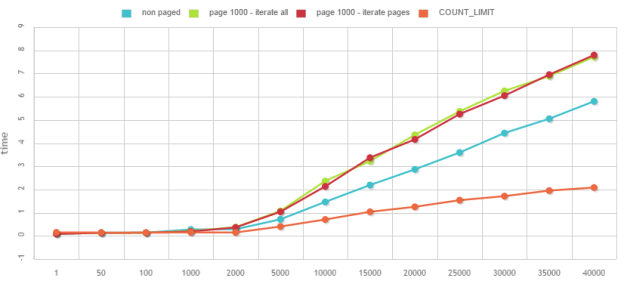
When counting, it may be strange, but it is a lot better to expect something. Or if you can’t, at least have a limit over which the result doesn’t really matter, you are happy enough knowing it is more than this limit. Actually in most case that’s enough. For UI you would say over something, to forbid an operation you usually have a limit over which you will forbid it anyway, and so on. Of course, if you want the exact number of item, it can be done but it will be a lot slower.
Benchmarks will be counting the number of documents in a 5/4/10 folder hierarchy, meaning 5 level of sub-folders, each level with 4 sub-folders and 10 documents. This is about 55,000 documents in 5,500 folders. And we don’t always want to count exactly, in the benchmarks we will ask if there is more than 5, 10, 15,50 … until 40,000 documents. Because sometimes knowing than there is more than 50 documents is enough to forbid an operation.
Now let’s introduce the few options we have to count.
Continue reading